EARL: Equi-Angular Representation Learning
Despite the success of the fixed ETF classifier in both the imbalanced training and offline CL, the ETF classifier has not yet been explored for online CL due to the necessity of sufficient training for neural collapse. To be specific, streamed data are trained only once in online CL, which makes it harder to induce neural collapse than in offline CL which supports multi-epoch training.
To learn a better converged model without multi-epoch training for online CL, we propose two novel methods, each for the training phase and the inference phase, respectively. In the training phase, we accelerate convergence by proposing preparatory data training. In the inference phase, we propose to correct the remaining discrepancy between the classifiers and the features using residual correction.
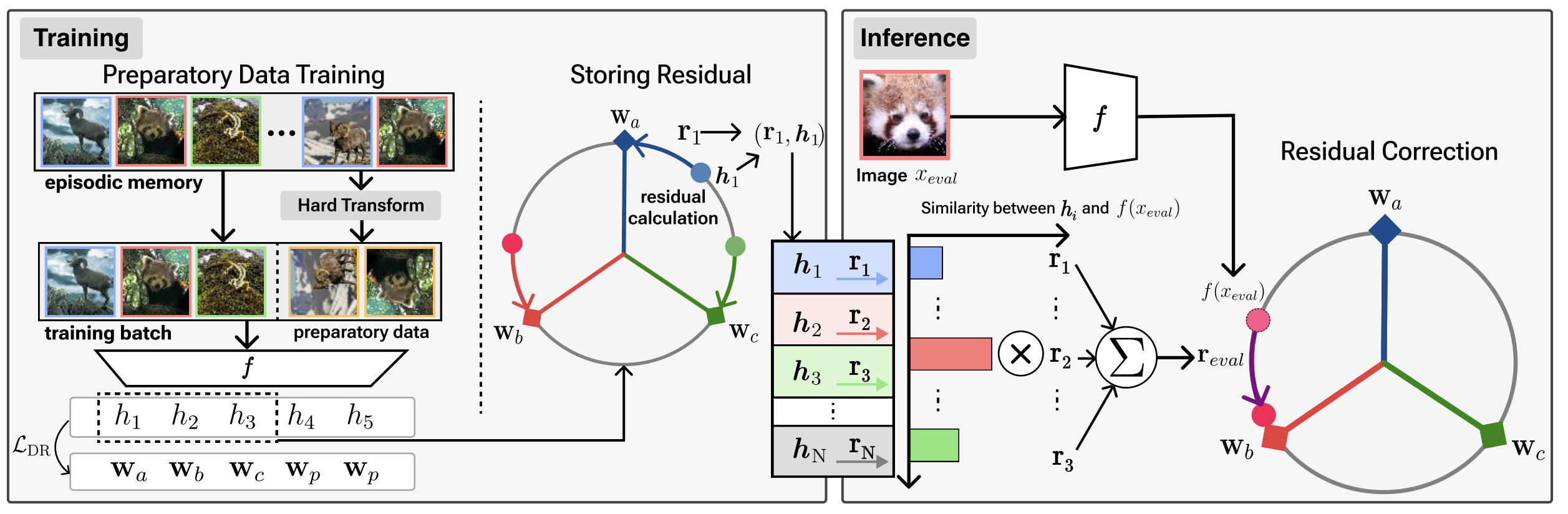
How to Make Preparatory Data?
For preparatory data to have a different representation from existing classes when trained, their image semantics should be distinguishable from the existing classes, provided that they contain enough semantic information to be considered as an image (i.e., not a noise). There are various approaches to synthesize images with modified semantics, such as using the generative model or the negative transformation. We use the negative transformation, as the generative model is expensive in computation and storage, which is undesirable for CL scenarios with limited memory and computations. On the contrary, negative transformation is relatively efficient in computation and storage and is reported to create images with semantics different from the original image. Speficially, we use negative rotation (rotation 90, 180, and 270 degrees) as negative transformation. We empirically observed that data generated through negative rotation have a distinct semantic class from the original class.
We summarize and illustrate the effect of each component in EARL. (a) In online CL, features of novel classes are biased towards the features of the previous class. (b) By training with preparatory data, we address the bias problem. (c) In inference, for features that do not fully converge to an ETF classifier, we add residuals to features that have not yet reached the corresponding classifier vectors, making features aligned with them. Purple arrow: the ‘residual correction’, Colors: classes.
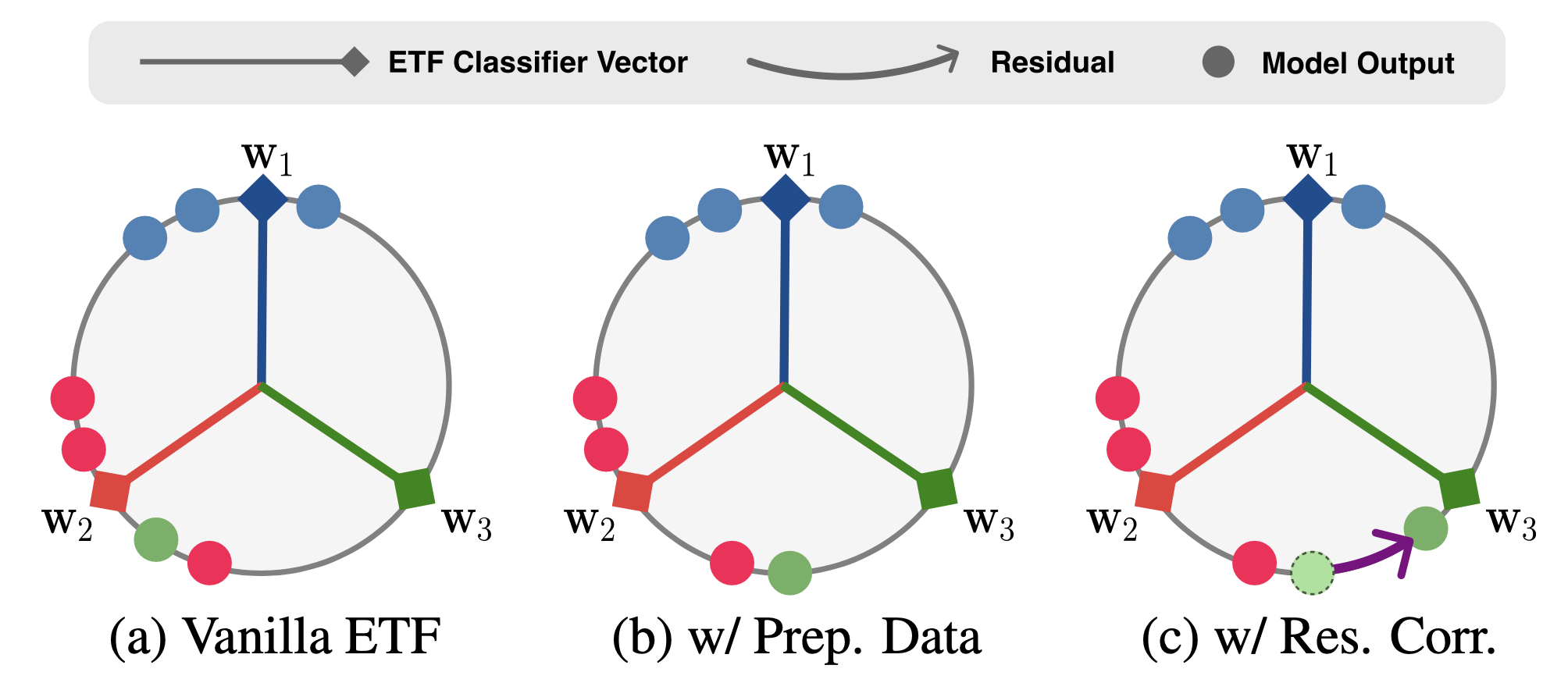
Effect of Equi-Angular Representation Learning (EARL).
Results
We compare the accuracy of the online continual learning methods, including EARL. As shown in the table, EARL outperforms other baselines on all benchmarks (CIFAR-10/100, TinyImageNet, ImageNet-200), both in disjoint and Gaussian-scheduled setups by large absolute margins. In particular, high A_AUC (area under the accuracy curve) suggests that EARL outperforms other methods for all the time that the data stream is provided to the model, which implies that it can be used for inference at anytime.
For more details, please check out the paper.

Comparison with State of the Art
Furthermore, we measure the Average Online Accuracy (AOA), which uses the newly encountered streaming data for evaluation before incorporating it into the training process.
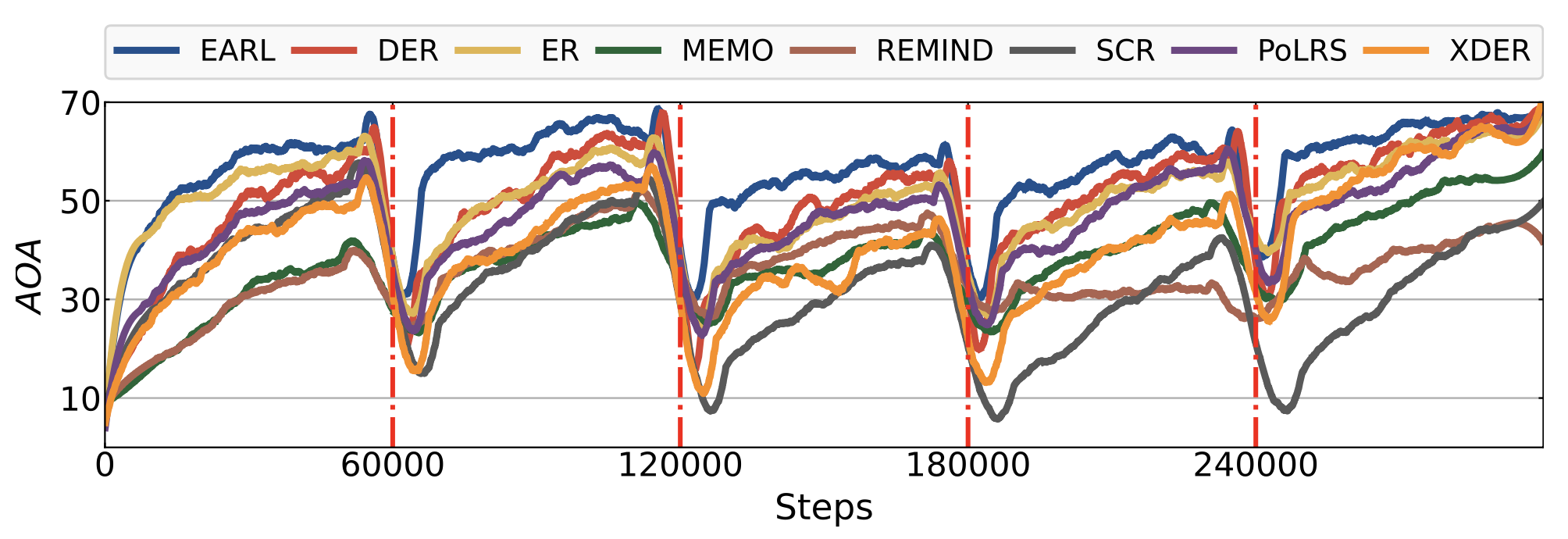
AOA (Average Online Accuracy) Plot
Ablation Study
We conduct an ablation study on the two components of EARL, preparatory data training and residual correction. Although both components contribute to performance improvement, preparatory data training shows a larger gain in performance.

Ablation Study. RC and PDT refer to preparatory data training and the residual correction.
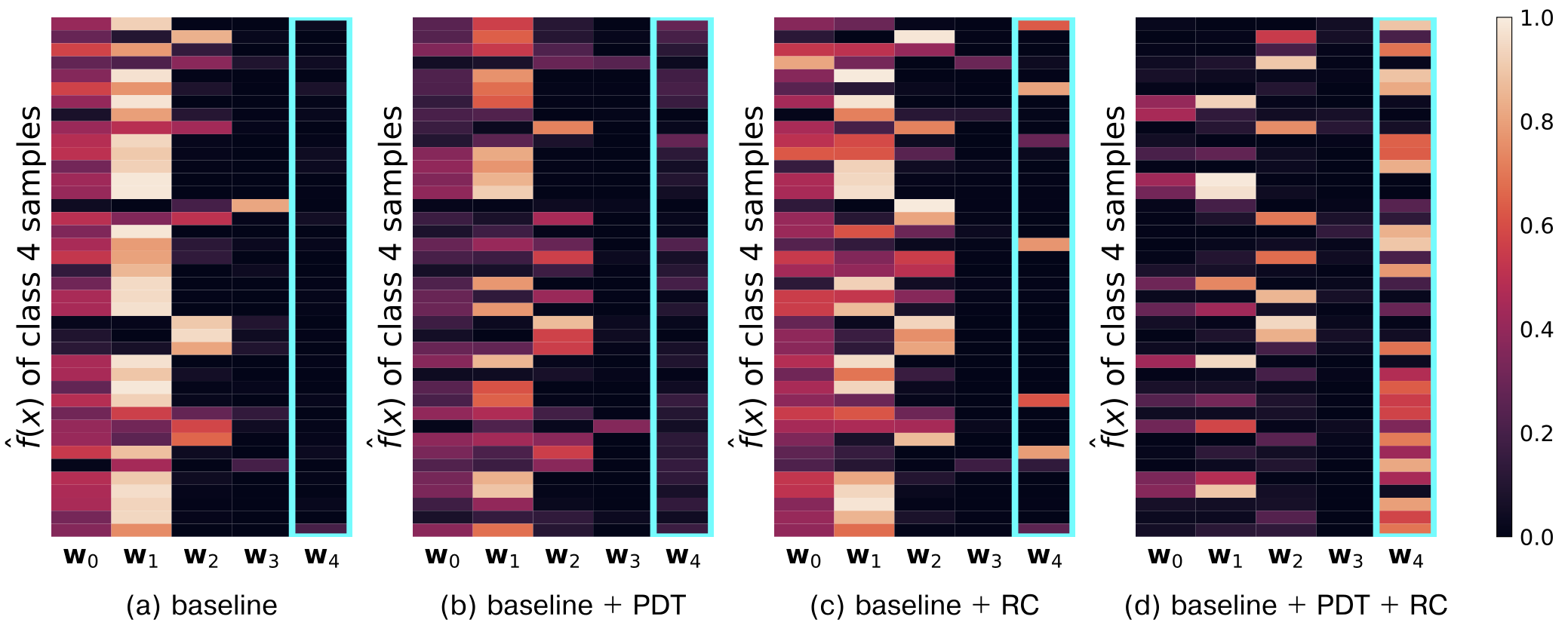
For further analysis, we visualizes the cosine similarity between the output features of 50 randomly selected test set samples of novel class ‘4’ and the classifier vectors wi. In baseline (a), the features of the class 4 are strongly biased towards the classifier vectors of the old classes (i.e., w0, w1, w2, w3), rather than the correct classifier, w4. (c) When residual correction is used, some samples show high similarity with w4 compared to the baseline. However, since incorrect residuals can be added due to the bias problem, more samples have high similarity with w2 than the baseline (i.e., wrong residuals are added). (b) When using preparatory data training, the bias toward w0 and w1 classes significantly decreases compared to the baseline. (d) Using both residual correction and preparatory data training shows a remarkable alignment with the ground truth classifier w4.